
TLDR: Write and Read Unicode from files with Python 2 and 3
Published on
Chatting with a friend, Mário Sérgio, about problems that happen when you migrate your codebase from Python versions, I came out with the idea of writing this TLDR.
I hope it can help someone that is trying to work with texts that contain Unicode characters that don’t fall back into the ASCII table like other than the roman alphabet and emoji.
On Python 2 there’s no distinction between byte and string. It leads us to eventually not correctly encode/decode the data when we deal with input and output. That kind of mistake can cause runtime errors like that:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 1: ordinal not in range(128)
Changing to Python 3, where byte and string are distinct types, the code in most cases stop working or presents weird behaviors like mixing text with their textual representation of the codification:
'ol\xc3\xa1'
The solution to write a code that runs across both versions is to follow the zen of python where it says that “Explicit is better than implicit” and always define what is byte from what is string:
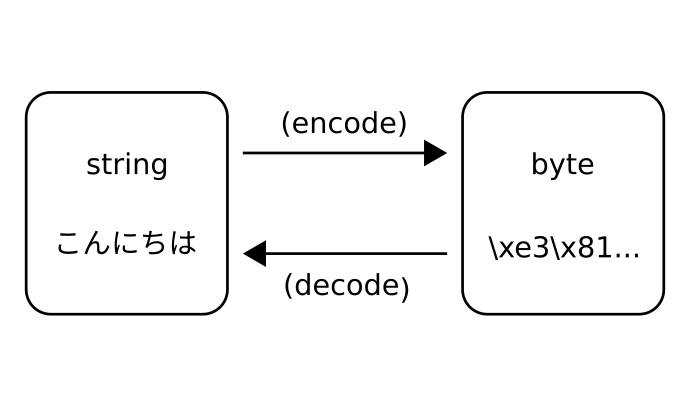
The following code opens a temporary file to write in byte mode and writes the content of a string that was encoded into byte using the utf-8 encoding. Then, the inverse process is done, opening the file for reading in byte and decoded to string to print to the terminal:
# -*- coding: utf-8 -*-
from __future__ import print_function, unicode_literals
import tempfile
unicode_file = tempfile.mktemp()
# escrita
with open(unicode_file, 'wb') as f:
f.write('こんにちは'.encode('utf-8'))
# leitura
with open(unicode_file, 'rb') as f:
print(f.read().decode('utf-8'))
The result is a code that runs in Python 2 and also in Python 3:


This work is licensed under a Creative Commons Attribuition-ShareAlike 4.0 International License .